
A Kubernetes Deployment is a resource object that provides declarative updates to applications. It enables administrators to describe the application’s life cycle, defining specific images, the desired number of pods, and more. The Kubernetes backend manages the Deployment process, performing an entire software update process without user intervention.
The Deployment object supports the concept of declarative configuration and a GitOps development style. The Deployment object defines the desired state, and Kubernetes mechanisms work to ensure the required resources exist in the cluster and achieve this desired state. This eliminates the need to manually update and deploy applications, which is time-consuming and may lead to human error.
Out of the box, the Deployment object supports basic deployment strategies like “recreate” and “rolling update” (described in more detail below). It can be customized to achieve more advanced progressive delivery strategies such as blue/green and canary deployments.
Pods and Deployments are the basic building blocks of large-scale Kubernetes environments, but they serve different purposes:
A pod is a unit including one or more containers that share storage and networking resources. Pods are the smallest application building blocks in a Kubernetes cluster. They can host entire applications or parts of applications.
Kubernetes developers or administrators define one or more pods required to run an application, and Kubernetes runs and manages them automatically. Kubernetes determines which cluster node (physical host) should run each pod in the cluster (this is called “scheduling” the pod on the node), and automatically restarts pods if they fail.
A Deployment is a management tool for controlling the behavior of pods. By default, Kubernetes runs one instance for each Pod you create. However, by defining a Deployment object, you can specify that Kubernetes should run multiple instances of the pod. Behind the scenes, the Deployment object creates ReplicaSets to run the required instances of the pod.
The Deployment object eliminates the need for administrators to manually run pods on Kubernetes nodes. A Deployment is a declarative configuration that performs all necessary steps to achieve the desired state. You can use simple configuration files to apply changes or updates to your entire cluster, saving time and making your Kubernetes cluster more scalable.
This is part of an extensive series of guides about microservices.
A StatefulSet is a workload API object for managing stateful applications. They let you ensure that pods are scheduled in a specific order, that they have persistent storage volumes available, and that they have a persistent network ID that is maintained even when a pod shuts down or is rescheduled.
Similar to Deployments, StatefulSets manage the behavior of pods. However, it differs from deployments in that it maintains a static ID for each pod. Pods are created from the same template, but each one has a separate identity, making it possible to maintain a persistent state across the full lifecycle of the pod.
| Deployment | StatefulSet |
|---|---|
| Intended for stateless applications | Intended for stateful applications |
| Pods are interchangeable | Pods are unique and have a persistent ID |
| All replicas share the same volumes and PersistentVolumeClaims | Each pod has its own volumes and PersistentVolumeClaims |
A ReplicaSet is a Kubernetes object that runs multiple instances of a pod and ensures a certain number of pods is running at all times. The goal is to ensure that the applications running in the pods have enough resources and do not experience downtime, even if one or more pods fail.
When a pod fails, the ReplicaSet immediately starts a new instance of the pod. At any given time, if the number of running instances does not match the specified number, it scales up and creates another instance of the pod with the same label. If there are extra pods, the ReplicaSet scales down by removing them. In addition, the ReplicaSet helps perform load balancing between multiple instances of the pod.
By contrast, a Deployment is a higher-level concept that manages ReplicaSets and provides declarative updates to pods along with many other features. The Kubernetes documentation recommends that users do not directly work with ReplicaSets, instead using Deployments or alternative mechanisms like StatefulSet. The Deployment or StatefulSet can then create ReplicaSets on the user’s behalf.
Kostis is a software engineer/technical-writer dual-class character. He lives and breathes automation, good testing practices, and stress-free deployments with GitOps.
In my experience, here are tips that can help you better adapt to using Kubernetes Deployments:
A Kubernetes Deployment object has the following lifecycle stages:
The code in this section is based on examples from the Kubernetes documentation.
Here is an example of a Deployment object that creates a ReplicaSet with three NGINX pods. The .spec.selector field defines how the Deployment identifies pods to manage. In the template field and its sub-fields, you specify the pods that should be run by the Deployment object.
apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment labels: app: nginx spec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: —name: nginx image: nginx:1.14.2 ports: —containerPort: 80
To apply the above Deployment object in your cluster and view its status:
kubectl apply -f https://k8s.io/examples/controllers/nginx-deployment.yaml
2. Check if your Deployment was successfully created by running kubectl get deployments . The output will be similar to this:
NAME READY UP-TO-DATE AVAILABLE AGE nginx-deployment 0/3 0 0 1s
3. Check Deployment rollout status by running kubectl rollout status deployment/nginx-deployment . The output will show how many of the 3 replicas have been updated, and when the Deployment is complete.
4. Wait a few seconds and run kubectl get deployments . You should now see output indicating that the Deployment completed:
NAME READY UP-TO-DATE AVAILABLE AGE nginx-deployment 3/3 3 3 18s
5. To see the ReplicaSets created by the Deployment, run kubectl get rs . The output will be similar to this:
NAME DESIRED CURRENT READY AGE nginx-deployment-75675f5897 3 3 3 18s
6. To see the labels automatically generated for each Pod, run kubectl get pods --show-labels . The labels for each container will contain the name of the app (nginx) and a unique pod template hash, like this:
app=nginx,pod-template-hash=3123191453
Deployment strategies are different ways of rolling out a new version of an application in a Kubernetes cluster.
Kubernetes offers the following two deployment strategies out of the box:
The recreate strategy kills the currently running pod instances and creates new instances running the latest version. This is often used in development environments where users are not actively working on the instances and downtime is acceptable.
Recreating pods completely updates the state of the pods and applications. So this deployment strategy results in downtime and can interrupt current operations for users, meaning it is not recommended for production environments.
A rolling update deployment strategy allows for a sequential, gradual transition from one application version to another. In this deployment, a new version of a ReplicaSet is started alongside the existing ReplicaSet with the old version. The Deployment object launches new pods using the new version of the pod specification, and when the new pods start successfully, shuts down the old pods.
Rolling updates allow you to migrate between versions in a safe and controlled manner, but the transition to the new version can take time. Also, it can be difficult to roll back or interrupt the deployment in the middle if something goes wrong.
The following are more advanced deployment strategies, which are not offered out of the box in Kubernetes. You can achieve them by customizing Kubernetes or using a dedicated tool like Argo Rollouts (learn more below).
The blue/green strategy allows for a quick transition from the old application version to the new version, and enables testing of the new version in production. “Green” refers to the new version, which is deployed alongside the old version, called the “blue” version.
After the “green” version is deployed and passes basic tests, you can transition traffic from the current “blue” version to the “green” version. After switching over traffic, you should carefully monitor the new version, and if you see major issues, switch traffic back to the “blue” version. Otherwise, users continue to use the “green” version, which becomes the new “blue” version.
The downside of a blue/green deployment is that it requires twice the resource utilization, at least during the staging and cut-off period.
In a canary deployment, a small number of users are routed to the new version of the application. The application runs on a small set of pods to test new functionality in production. If there are no major issues and users are satisfied with the change, the canary version is expanded to more users, until eventually, it completely replaces the old version.
Canary deployments are great for testing new features with small groups of users and can be rolled back easily. Therefore, canary deployment is a good way to determine how new code will affect the system as a whole and whether it will have a positive or negative impact on user experience.
A downside of canary deployment is that the application must be able to run two versions at the same time, which is not supported by many legacy applications. In addition, for an effective canary strategy, you also need a service mesh or network gateway to split traffic between current and canary versions.
In the context of Kubernetes, A/B testing refers to a deployment in which traffic is distributed between different versions of an application based on certain parameters.
Unlike a canary deployment, which routes users based on traffic weights (e.g. 10% of traffic views the canary and 90% views the original version), A/B testing makes it possible to keep both versions running at all times. With canary deployments, the old version is always phased out and only one version remains.
One of the main uses of this deployment strategy is testing several options of a new feature, and then rolling out only the most successful versions to all users. Like canaries, A/B test deployments are complex and might require a service mesh for fine-grained control over traffic distribution.
A shadow deployment lets you test production loads on a new version of the application, without users being aware of the change. The shadow deployment never gets user traffic – it is a clone of prod which is not visible to users.
A shadow deployment releases a new version alongside an existing version, allowing for testing in a realistic production environment. When the stability and performance of the new version meets the defined requirements, the new version is rolled out to users.
Shadow deployments work best when the new version of the application does not directly impact users, but might have performance or other non-functional impacts. Similar to a blue/green deployment, they are more expensive because they require more resources than a regular deployment. However, unlike blue/green deployments, a shadow deployment can sometimes be run with a subset of the resources of the production version, making it more cost effective.
The native Kubernetes Deployment object only supports the RollingUpdate and Recreate strategies. Recreate is not a progressive delivery strategy, and results in application downtime. RollingUpdate is a bit more advanced, but provides only basic set of safety guarantees (readiness probes) during an update. It is suitable for some application update scenarios.
However, the rolling update strategy has many limitations. It provides limited control over the speed of the rollout, cannot control traffic flow to the new version, is not suitable for stress tests or one-time tests, cannot query external metrics to verify an update, and is not able to abort and rollback the application update.
In mission critical production environments, the rolling update functionality provided by the Deployment object is usually not suitable. There is no control over the impact of changes, and depending on the Deployment configuration, may roll out too quickly for comfort. There is also no automated rollback option if something goes wrong. These issues have raised the need for dedicated tools that can provide more advanced options for deployment in Kubernetes clusters.
Argo Rollouts is a Kubernetes controller and set of CRDs which provide advanced progressive deployment capabilities—including blue/green, canary deployments, canary analysis, and experimentation. It is designed to be very similar to the traditional Kubernetes Deployment object, so that operators familiar with Deployments can immediately start using it.
Code examples in this section are taken from the Argo Rollouts documentation.
Argo Rollouts provide a Rollout object, similar to a Deployment object, which manages ReplicaSets but also modifies Service resources during the application update.
When defining the Rollout specification (similar to a Deployment YAML configuration), you can provide a reference to the active service and a preview service, both running in the same namespace. The active service is used to direct traffic to the old version, while the preview service is used to direct traffic to the new version.
The Rollout controller inserts a unique hash of the ReplicaSet into the selectors of these services to ensure proper traffic routing. This lets you define an active version and a new, preview version, and smoothly migrate ReplicaSets from preview to active.
When you make a change to the .spec.template field of a rollout, the controller creates a new ReplicaSet. Initially, the controller sends traffic to the old ReplicaSet. When the new ReplicaSet is available, the controller modifies the active service to point to it. After a certain waiting period configured in the Rollout specification, the controller scales down the old ReplicaSet.
The following code shows how to define a Rollouts specification that performs blue/green deployment.
apiVersion: argoproj.io/v1alpha1 kind: Rollout metadata: name: rollout-bluegreen spec: replicas: 2 revisionHistoryLimit: 2 selector: matchLabels: app: rollout-bluegreen template: metadata: labels: app: rollout-bluegreen spec: containers: —name: rollouts-demo image: argoproj/rollouts-demo:blue imagePullPolicy: Always ports: —containerPort: 8080 # up to here the configuration is identical to a Deployment # from this point onwards you define advanced deployment options strategy: blueGreen: # activeService is a mandatory field specifying the service to update with the new template hash at time of promotion. activeService: rollout-bluegreen-active # previewService is an optional field specifying the service to update with the new template hash before promotion. # This allows the preview stack to be reachable without serving production traffic. previewService: rollout-bluegreen-preview # autoPromotionEnabled defines whether to pause the rollout before promotion, or automatically direct traffic to the new stack as soon as ReplicaSets are ready. # If this is set to false, Rollouts can be resumed using: `kubectl argo rollouts promote ROLLOUT` autoPromotionEnabled: false
Because there is no accepted standard for canary deployment, the rollout controller allows users to outline how to perform canary deployment. The user can define a list of steps the controller will use to manipulate the ReplicaSet when the .spec.template changes. During each step, a bigger fraction of total traffic is exposed to the new version.
Each step in the canary deployment has two fields:
When the controller reaches a rollout step defined as pause rollout phase, it sets the PauseCondition structure to append to the .status.PauseConditions field. If the pause struct has a duration field set, the deployment will not proceed to the next step until it waits for the value of the duration field. Otherwise, the rollout waits indefinitely until it receives user input.
These two parameters together let you declaratively describe how to execute the canary deployment.
Here is an example of a Rollouts object implementing a canary strategy:
apiVersion: argoproj.io/v1alpha1 kind: Rollout metadata: name: example-rollout spec: replicas: 10 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: —name: nginx image: nginx:1.15.4 ports: —containerPort: 80 minReadySeconds: 30 revisionHistoryLimit: 3 # up to here the configuration is identical to a Deployment # from this point onwards you define advanced deployment options strategy: canary: #Indicates that the rollout should use the Canary strategy maxSurge: "25%" maxUnavailable: 0 steps: —setWeight: 10 —pause: duration: 1h # 1 hour —setWeight: 20 —pause: <> # pause indefinitely
Codefresh lets you answer many important questions within your organization, whether you’re a developer or a product manager. For example:
What’s great is that you can answer all of these questions by viewing one single dashboard. Our applications dashboard shows:
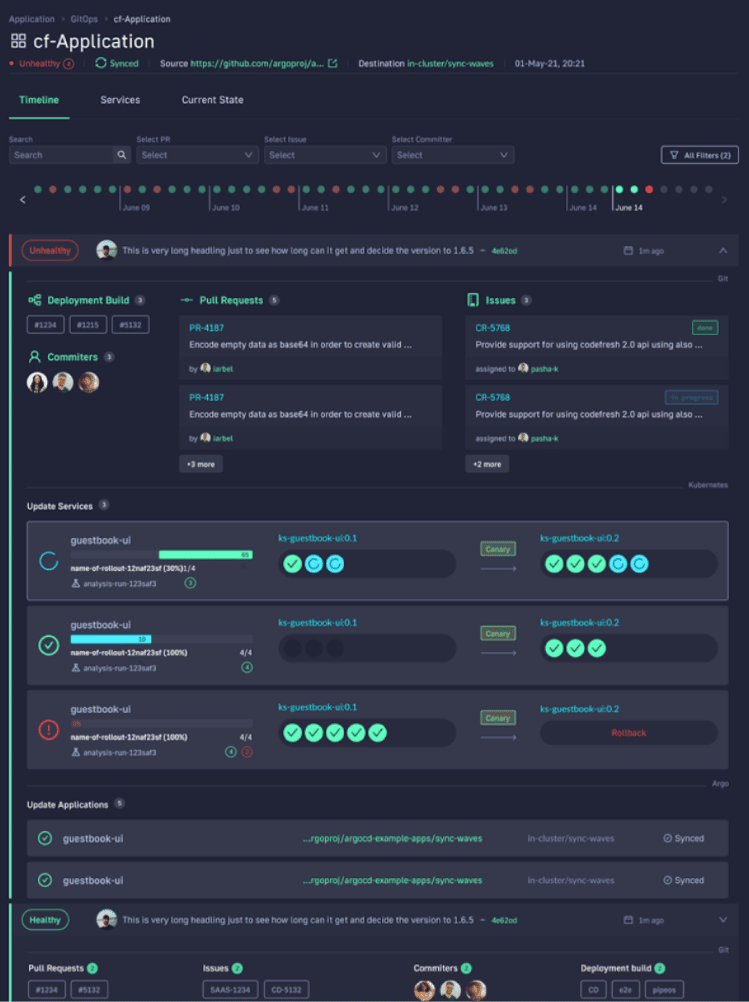
This allows not only your developers to view and better understand your deployments, but it also allows the business to answer important questions within an organization. For example, if you are a product manager, you can view when a new feature is deployed or not and who was it deployed by.
Together with our content partners, we have authored in-depth guides on several other topics that can also be useful as you explore the world of microservices.
Authored by CodeSee
Authored by NetApp
Authored by Lumigo